HTTP Retrieval Benchmarks with Boost

Boost has recently released a feature which enables storage providers to serve HTTP retrievals (full piece retrieval and range requests) with booster-http. Ecosystem partners working on Filecoin Evergreen, perpetual storage initiatives, or doing storage deal replication have shared that full piece retrievals are beneficial to efficiently move these efforts forward. In addition, there is an option to perform range requests, which means clients can select a range of content in the full piece to retrieve.
We have performed load testing on booster-http and are sharing out results in hopes that these findings can help storage providers better understand how HTTP retrievals with Boost might work on their own setup. Anyone can download our load testing tools and run their own load testing.
Environment
For this HTTP load testing effort, we tested on filcollins, which is our team’s production grade petabyte scale storage provider. Below you will find the hardware details for filcollins, which includes 4 instances - 2 cpu instances and 2 gpu instances.
CPU Instance Type
CPU
model name: AMD EPYC 7F32 8-Core Processor
Storage
5 x 1.8TB HDDs running as a striped array, designated for scratch area
2 x NVMe running as a stripped array, designated for scratch area
Memory
1 TB RAM
GPU Instance Type
CPU
model name: Intel® Xeon® Gold 6242 CPU @ 2.80GHz
Memory
502 GB RAM
GPU
4 x NVIDIA Quadro RTX 6000 (24 GB GDDR6)
Storage
500 TB Ceph system designated for long term storage of sealed/unsealed sectors
3 x 900 GB HDDs running as a striped array, designated for scratch area
Load Testing Process
In terms of process to setup the HTTP benchmark testing, we created an artificial limit on the outbound connection to simulate the 10GBit and 1GBit connections. On both, we also setup an artificial one way latency of 40ms. We simulated downloads using a load testing framework called K6.
There are two scenarios that were tested with varying concurrency: raw retrievals and Boost retrievals.
- Raw: NGinx serving files directly from disk with no Boost or Filecoin involved.
- Boost: done via booster-http.
These protocols were tested in 2 main modes: full-fetch and range requests.
- full-fetch refers to full Filecoin piece retrievals.
- range requests refers to retrieving a specific range of content within the full Filecoin piece. For this load testing exercise, we tested across multiple ranges - 1 MiB, 10 MiB, and 100 MiB.
Results
Full piece retrievals
The results of our load testing for 1GB and 10GB connections for full piece retrievals are similar. There are small differences in latency, but not by a significant amount (all less than a second).
Range requests
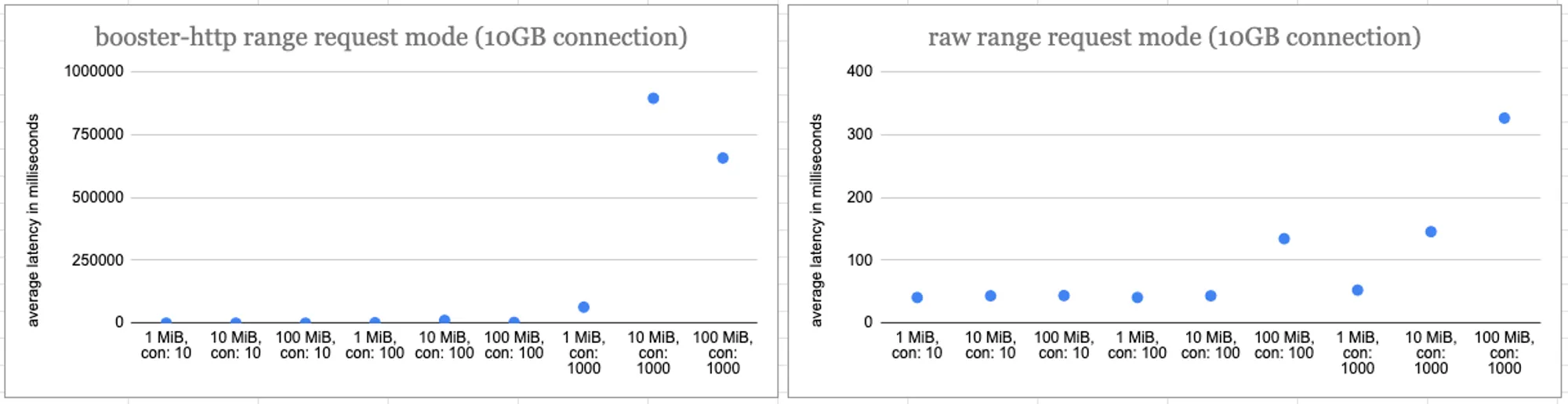
The results of our load testing for 1GB and 10GB connections for range requests also yielded similar results at lower concurrencies. The differences between raw retrievals and booster-http are not that noticeable (less than a second).
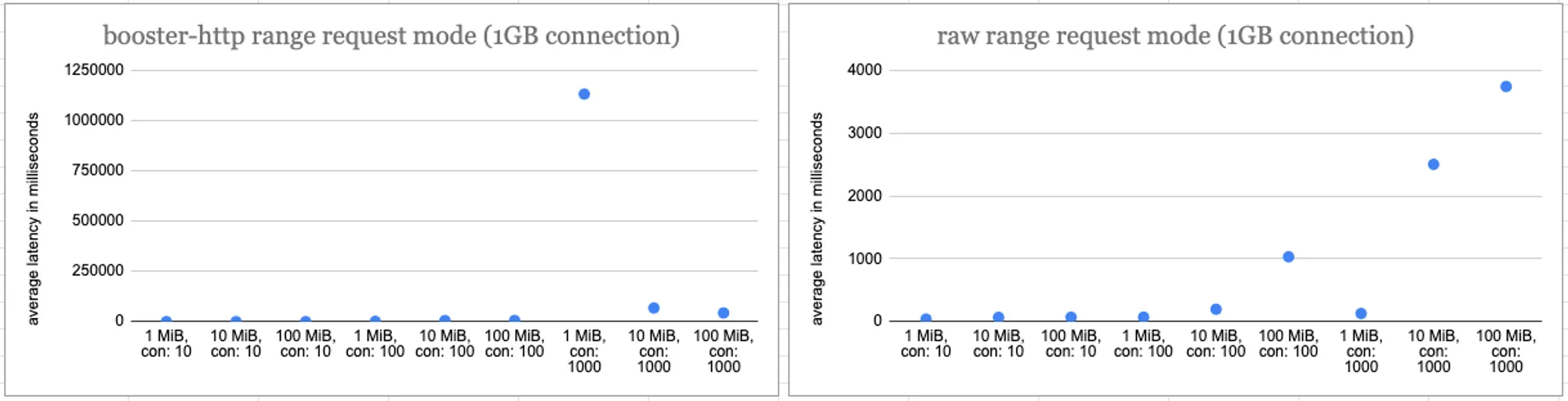
However, as concurrency goes up to 1000, you can see that boost range request retrievals are very slow (for 10GB connection, up to 10 minutes for larger data ranges), and the success rate also drops in comparison to HTTPS retrievals (40% to 60% success rates). There is a drop off in ability for Boost to start responding to the request, especially with high concurrent requests.
The team is committed to investigating this issue and figuring out why this is the case. This slow down only occurs at high concurrency levels. If any storage providers observe similar behavior, or have use cases which require this level or higher concurrency, we would like to learn more. In addition, if you have work loads that you would like help testing, please reach out to the team. You can find us on GitHub or #boost-help in Filecoin slack.