
How to be an Index Provider
This is the third blog post in a series of posts on the Network Indexer. The first blog post introduced the Network Indexer as a concept while the second blog post dived deeper into how it works internally in order to enable finding content providers for billions of addressable content out there.
Building on top of the previous posts, this blog post will discuss in depth on how to be an index provider to network indexer and become an Index Provider.
What is an Index provider?
An Index provider is essentially a content provider that does two additional things:
- Tells the network what content it has by advertising their multihashes, and
- Supplies additional information on how the content can be retrieved.
Process Overview
The following illustrates an overview of steps a typical index provider takes: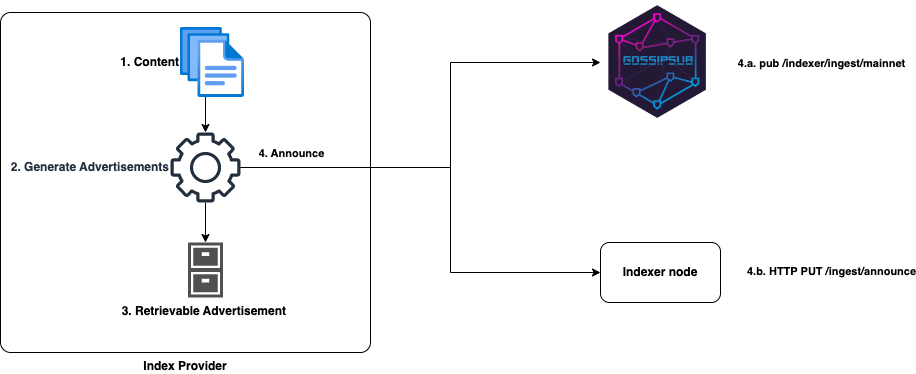
Content: Some new addressable content is stored on the provider. The provider extracts the multihashes from the content CIDs, a.k.a. Entries.
- Generate Advertisements: The provider assembles the entries along with metadata on how to retrieve the content in a data structure called an Advertisement.
- Retrievable Advertisements: The provider stores the advertisement just like any other piece of content and makes it available for retrieval. Advertisements themselves are addressable content.
- Announce (optional): The provider announces to the network that there is new content being advertised. The announcement may be published in two ways:
- Gossipsub announcement: Published on a well-known gossipsub topic, by default
/indexer/ingest/mainnetover libp2p. - HTTP announcement: An explicit
PUTrequest is made to a known network indexer instance over HTTP transport protocol.
- Gossipsub announcement: Published on a well-known gossipsub topic, by default
The indexer nodes listen and react to announcement messages which triggers the advertisement ingestion mechanism that ultimately results in indexing of the content by the network indexer.
Let’s dig deeper into each of the steps.
Generating Advertisements
An advertisement is the code data structure that conveys information about the content hosted by a provider to the network indexer. The snippet below outlines this data structure in IPLD schema format:
type Advertisement struct {
PreviousID optional Link
Provider String
Addresses []String
Signature Bytes
Entries Link
ContextID Bytes
Metadata Bytes
IsRm Bool
ExtendedProviders
}
Advertisement IPLD schema
Here is a quick overview of what each of those fields represent:
- Previous ID: IPLD link to the previous advertisement, where the absence of the link represents the ad is the earliest in the chain.
- Provider: libp2p Peer ID of the content provider
- Addresses: the list of addresses over which the content can be retrieved
- Signature: the advertisement signature, signed by the identity of the content provider.
- Entries: IPLD link to entries that capture the hashes of content hosted by the content provider.
- ContextID: the key that uniquely identifies the advertisement metadata published by the content provider.
- Metadata: the encoded description of protocols over which the data is retrievable
- IsRm: whether the advertisement removes previously advertised content.
- ExtendedProviders: the list of alternative providers for the data.
Advertisement Chain
The advertisements are chained together, where each advertisement is effectively a diff of content hosted by the providers. The collection of all advertisements together represents a full list of all multihashes on the host. The following figure illustrates how advertisements are chained together: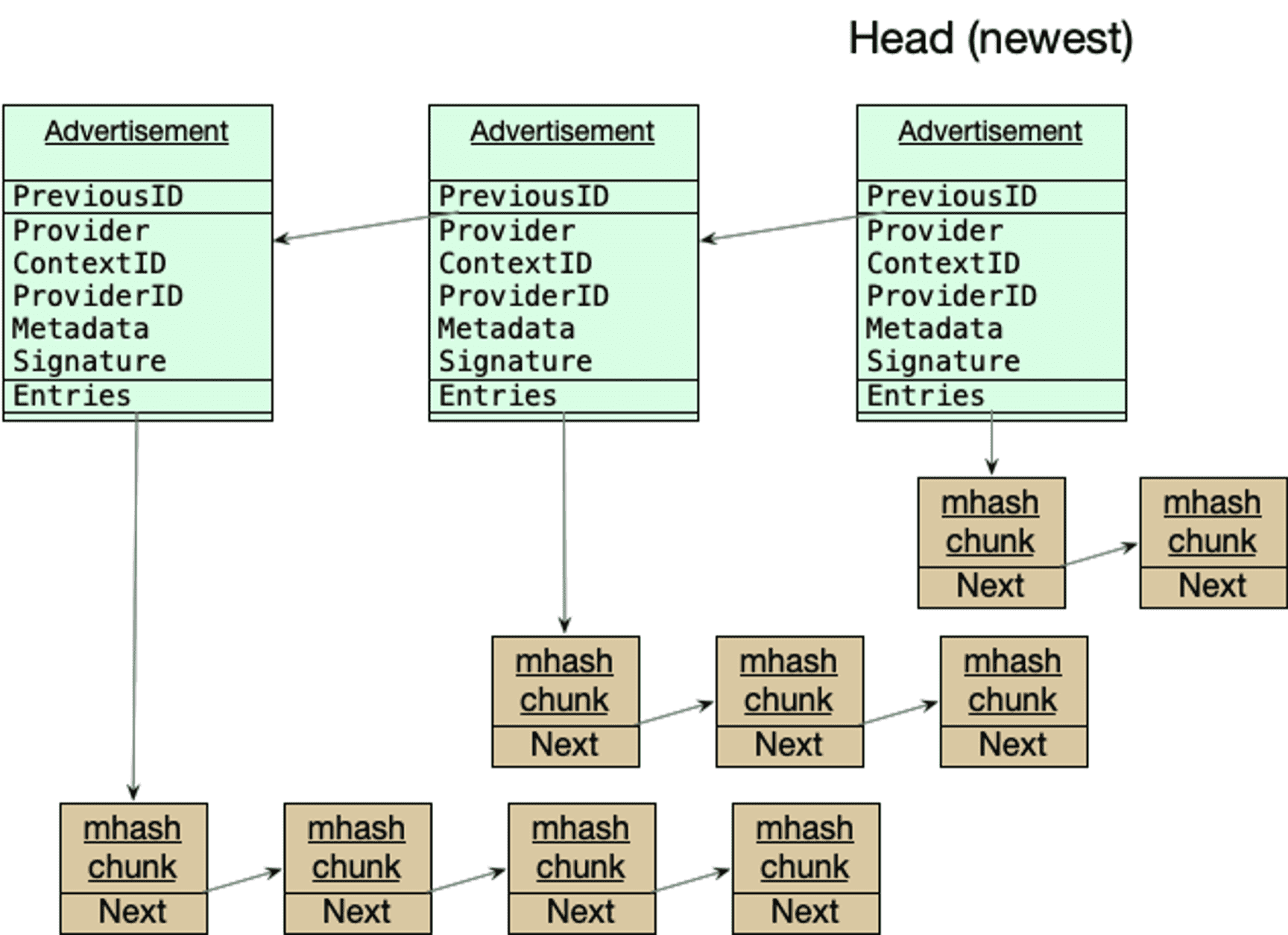
Entries
Entries capture a list of mutlihashes that are hosted by a content provider. It can be structured as:
EntryChunk, orHAMT
Entry Chunk Chain
The EntryChunk chain Uses the following IPLD schema:
type EntryChunk struct {
Entries []Bytes
Next optional Link
}
EntryChunk IPLD schema
Similar to advertisements, EntryChunk s are also chain together as a way to facilitate pagination of the list of multihashes using IPLD links. The primary Entries list is the array of multihashes in the advertisement. If an advertisement has more CIDs than fit into a single block for purposes of data transfer, they may be split into multiple chunks, conceptually a linked list, by using Next as a reference to the next chunk.
In terms of concrete constraints, each EntryChunk should stay below 4MB, and a linked list of entry chunks should be no more than 400 chunks long. Above these constraints, the list of entries should be split into multiple advertisements. Practically, this means that each individual advertisement can hold up to approximately 40 million multihashes.
HAMT
The HAMT must follow the IPLD specification of HAMT ADL. The HAMT data structure is used as a set to capture the list of multihashes being advertised. This is where the keys in the HAMT represent the multihashes being advertised, and the values are simply set to true.
https://github.com/ipld/go-ipld-adl-hamt
https://ipld.io/specs/advanced-data-layouts/hamt/spec/
Entry Chunk Chain Vs. HAMT
You can use either of the data structures to represent the entries in an advertisement. But which one to pick depends on your use case.
Entry Chunk Chain is much simpler: it is a chain of IPLD nodes that each have an array of multihashes. The multihashes are not sorted; it means to get the list all the multihashes, say with a certain prefix, one would have to ingest the entire chain. Because there is only one link to the next chunk the chunks follow strict ordering but also they cannot be traversed in parallel: we will only know the link after next by traversing the next link.
HAMT on the other hand uses a specialized map data structure to organize multihashes. Because of this specialized organization, it offers efficient search through the map to find multihashes with specific prefix. This can become very handy when it comes to distribution of responsibility across multiple nodes for example; more on this on future posts. On the negative side, it is a more complicated data structure and demands understanding of the total number of multihashes and some research to pick the right HAMT values for bit-width and bucket size.
Metadata
The Metadata captures information about the protocols over which the data can be retrieved. By convention it starts with a varint, as protocol ID that provides a hint on how to decode the remaining bytes. Metadata is explicitly designed to be extensible: it can support any protocol that you like as long as retrievers of data understand the protocol ID. Indexer nodes simply treat this as an array of bytes with a maximum of 1KiB size limit.
This field supports encoding for multiple protocol IDs, where the requirement is that protocol sections should appear in ascending order of their protocol ID value. There are currently two well
known protocol IDs:
- Bitswap: which is simply a fixed varint of value
0x0900with no further bytes, and - GraphsyncFileCoinV1: which uses the protocol ID 0x0910 and specifies how content can be downloaded from Filecoin storage providers by encapsulating the following information encoded as CBOR:
type GraphsyncFilecoinV1 struct {
PieceCID Link
VerifiedDeal Bool
FastRetrieval Bool
}
GraphsyncFileCoinV1 metadata IPLD schema
Typically, the protocol IDs are added to the multicodec CSV table. But it is not strictly required; as the retrieval client understands the metadata you are free to encode your own protocol with your own bespoke non-clashing protocol ID.
Announcing Advertisements
Once the advertisements are formed, an announcement is made by the index provider in order to propagate its existence, and consequently trigger the polling of the advertisement’s actual content by the network indexers. The announcements can be sent in two ways:
- GossipSub, or
- Direct HTTP announcements.
If indexers already know about the announcing provider, announcements for each new advertisement are not strictly necessary.
GossipSub Announcement
GossipSub announcements use the libp2p gossipsub protocol over a well known topic, called /indexer/ingest/mainnet. Indexer nodes listen to the messages published on that topic to detect:
- what the latest advertisement CID is, and
- where it can be fetched from.
They then contact the peer to initiate fetching of the advertisement chain.
HTTP announcement
Direct HTTP announcements require a well known indexer endpoint to be configured on the content provider side. Once an advertisement is formed, the content provider sends a PUT request to a well known endpoint, /ingest/announce, with body of the request containing the same information as the gossipsub messages.
The interaction on the indexer nodes upon receiving the direct announces is the same; the respond with 204 Accepted and passively call the peer to fetch the advertisement chain.
Fetching Advertisements
As eluded to earlier, the advertisement chain is pulled by the indexers; this is a key design decision that helps the indexer nodes to scale and be able to fetch content from a large number of providers. By making the advertisement fetch passive, the indexer nodes have the opportunity to batch the fetch requests in a case where there are a lot of provider announcements.
It also allows the indexers to control what to fetch: an indexer node would only fetch the portion of advertisement chain that it has not seen before by keeping track of the last processed advertisement CID internally.
To facilitate fetching, the providers need to expose and endpoint that is accessible by the indexer nodes. Two transport protocols are currently supported:
- HTTP, and
- DataTransfer over GraphSync
The announcement messages would carry information about which transport protocol is offered by the content provider.
Modifying Advertised Content
A provider is able to change the state of content it has advertised by specially crafted advertisements that relax the need for re-advertising entries. This is to allow efficient modifications without having to re advertise the entries every time.
Here is a quick overview of most common use cases on how to modify the advertised content via further advertisements:
- Content removal: Publish a new advertisement that uses a special CID
no-contentas theEntrieslink, withIsRmset to true and the sameProviderandContextIDas the advertisement that added the content. - Retrieval Protocol Change: Publish a new advertisement that does not specify the
Entrieslink, withIsRmset to false and the sameProviderandContextIDas the advertisement that added the content, only change the newMetadata. - Retrieval Address Change: Simply publish new advertisements with the new address and the address mapped to the provider ID gets updated for all previously advertised content.
See ingest schema documentation for further information on how to modify advertised content.
Note that remove all content is not currently supported.
IPNI also supports Extended Provider Families. This feature allows a provider to expand the list of other providers the data can be retrieved from along with the retrieval protocols. Stay tuned on upcoming blog posts dedicated to Extended Provider Families.
Verifying Advertisements
The index-provider library offers a CLI tool that can be used to verify that the advertised content is correct from both the content provider and indexer side. It can check that a content provider is exposing the chain correctly such that it is accessible by the network indexers. On the indexer side, it can then check that the advertised content is indeed ingested by the indexers and is discoverable via the query APIs associated to the correct provider.
See installation guide here, and run provider verify-ingest --help for more information.
Resources
If you are interested in participating in Indexer network or learning more about Indexers, you may find these resources helpful:
- cid.contact (content routing homepage)
- docs.cid.contact (Indexer gitbook)
- ipni (Filecoin slack channel)
- Indexer Implementation
- Index Ingestion
- Creating an Index Provider
- Index Providing Deck

